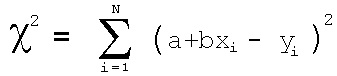
It has long been popular to use linear regression and least squares polynomial fitting for the determination of instrumental calibration graphs. It is simple to compute and for the case of normally distributed uncorrelated random errors it is provably optimal. However, there are robust alternatives which may in some circumstances be preferred.
Experimental errors are seldom if ever uncorrelated or randomly drawn from a normal distribution, and most practical calibration techniques use some form of error weighting to allow flexibility. One insidious problem which is quite common is that detector response tails off slightly at very high concentrations, leading to a systematic error. And the effect of least squares tends to strongly weight the fit towards the largest values. The effect is to compromise results measured for low concentration samples with large systematic errors.
Problems of this sort are particularly noticeable with the highly linear wide dynamic range ion counting detectors used in ICP-MS and to a lesser extent ICP OES and AES. It shows up as systematic errors in low concentrations.
For the purposes of illustration I will consider determining the best fit line y = a + bx given a small dataset and using uniform weighting to simplify the model. Real calibration would associate an error estimate with each calibration point and weight them inversely in proportion to their error estimate.
Least squares fitting is derived from minimising the expression:
The alternative method of robust calibration is called minimum 1-norm and it has the great advantage that it more nearly does what a trained analyst would do on looking at a calibration graph by eye - namely draw a line which minimises the absolute deviation between the calibration points and the line. It has the same number of points above and below the fitted line.
Minimum 1-norm is derived from minimising the expression:
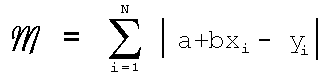
I will consider here a simple linear model calibrated over a few decades of concentration range using the common sequence of 0.1, 1, 10, 100 calibration solutions and uniform error weighting. This is a very bad idea as the fit is dominated by the two strongest solutions when this approach is used and it often leads to excessive systematic errors for low concentration data. It is quite a common analytical mistake, and the effects are much more pronounced on instruments with very high linear dynamic range.
Comparison of least squares with robust minimum 1-norm calibration
Target system
a = 33
b = 100
c = -0.05 Counts = a + b.x + c.x^2
Target Target x
Recovered Conc Counts Test Data Model C C2
-0.05 0.1 43 39.50 57.54 -18.04 325.55
0.90 1 133 128.02 142.41 -14.40 207.35
10.39 10 1028 1026.99 991.12 35.87 1286.46
100.58 100 9533 9474.74 9478.17 -3.42 11.73
______ ________
0.00 1831.08
Regression Output: 1-Norm Output:
Constant 48.1141 31
Std Err of Y Est 30.2579
R Squared 0.999971
No. of Observations 4
Degrees of Freedom 2
X Coefficient(s) 94.30053 94.91666
Std Err of Coef. 0.361259
Test Data Model C |C|
0.13 0.1 43 39.50 40.49 -0.99 0.99
1.07 1 133 128.02 125.92 2.10 2.10
10.56 10 1033 1026.99 980.17 46.82 46.82
100.11 100 9533 9474.74 9522.67 -47.92 47.92
______ _______
0.00 97.83
Or presented graphically
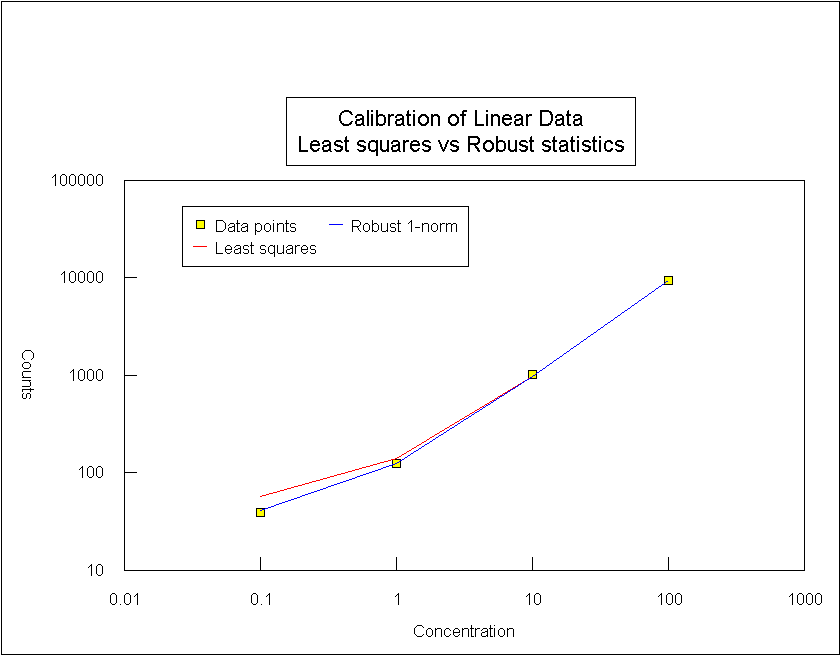
Both calibrations are accurately determined and for moderate to high concentrations give quite similar results. It is clear that the least squares calibration is much less accurate for the low values near the 0.1ppm calibration standard whereas minimum 1-norm retains accuracy over the calibrated range. Robust statistical methods deserve to be more widely used.
![]()